Application dependencies are like a city’s drainage system: when properly built and well managed, they become invisible in the apps we build, and we forget about them.
Setting up a Python project can be as easy as using pip to install all the dependencies we need before we can start. This may work — if we’re the only ones working on this project and we only intend to run it on our development machine — but it doesn’t scale. Scaling requires an automated CI/CD pipeline to make installing these dependencies repeatable.
We can clear up confusion about our project’s dependencies and make them easy to install by listing them in a requirements.txt file. Ideally, this would let us execute a single command to make our application ready to run — and as an added benefit, this makes the process repeatable. When we add requirements.txt to source control, we can easily use it to get our Python apps up and running on other developers’ machines, in CI/CD pipelines, and in production.
This approach may even be appropriate for some libraries, such as TensorFlow or NumPy, that contain substantial amounts of native C, C++, or Fortran code. However, this method only works well if the library offers a pre-built binary wheel on PyPI for our platform — and we’re willing to trust someone else’s binary.
Of course, we can’t always count on the availability of pre-built wheels for our target platform. Additionally, our employer’s security policy may requireus to build dependencies from scratch to ensure we’re not using a compromised native dependency. Coding our own dependencies is a great way to ensure the security of our software supply chain.
Building native dependencies from scratch has its challenges. Many of us are Python developers with little or no background in setting up and using native build toolchains. With enough trial and error, though, we can usually make them work on our development machines.
But what if we need to build our app’s native dependencies for multiple platforms in our CI/CD pipeline? It’s a common enough requirement, but it can be difficult to figure out where to start. Fortunately, there are a couple of ways to get the job done. We can manually install and update our dependencies (which takes time and effort) or use a modern package manager to set up an automated and repeatable CI/CD pipeline.
Managing Native Python Dependencies in a CI/CD Pipeline
For any application that we need to ship to end users, setting up a CI/CD pipeline is a good idea. Regardless of the type of app we’re shipping, a CI/CD pipeline gives us an automated, repeatable way to build, test, and package or deploy our app.
If our app only has pure Python dependencies and we only have to support one target platform, setting up a CI/CD pipeline is relatively easy.
But, if we have to build our native dependencies and support multiple platforms (for example, Linux, Windows, and macOS), things become complicated. In that scenario, we’ll need to:
- Set up a VM to run a build environment for each target platform.
- Integrate each build environment with our CI/CD platform, usually by installing an agent that lets the CI/CD platform invoke commands on our build machine.
- Install a complete build toolchain in each build environment. This usually varies from one operating system to the next. For example, if we’re building a dependency that contains C++ code, we will need to install GCC in our Linux build environment, the MSVC compiler in our Windows build environment, and Clang on macOS.
- Add any build automation tools that our native dependencies require, such as CMake, Meson, or Bazel.
We also have to deal with the issue of installing any headers and library files our native dependencies require. After all, if we want to build our native dependencies from source, we probably want to build the dependencies of our dependencies from source as well. The method for doing this varies: In our Linux build environment, we can probably use the built-in OS package manager to install library source packages. If we’re working with Windows, we’ll likely have to unzip our library source manually. If we develop on macOS, we’ll use a package manager like Homebrew if we can. But, if the Homebrew repository lacks the libraries we need, we’ll have to download and unzip them manually.
That’s a lot of work — even if everything goes perfectly. As Python developers, most of us aren’t build experts in C or C++. Let’s think back to the last time you tried to build a native Python dependency from scratch. Did it work perfectly on the first try? It usually requires some trial and error.
It gets even more complex if we need to build a library like NumPy, which contains both C and Fortran code. If setting up three C/C++ build environments is challenging, then buckle up: we’ll also need to install a Fortran build toolchain and native dependency source in all of our build environments.
We may also decide to keep local copies of our native dependency source code to ensure it hasn’t been tampered with. Keeping private copies of dependency source is a good security practice. However, it increases the risk of dependency confusion — that is, the risk that we mistakenly pull a remote copy of our dependency instead of using our private copy.
Setting up three native build environments for our CI/CD pipeline sounds like a lot of work. But, given enough time, it’s something we can handle.
Unfortunately, there’s usually more to the process. If we need to support both 32- and 64-bit builds on all three operating systems, we now need to set up a total of six build environments. And what if we need separate builds for Windows 7, Windows 10, Ubuntu, and CentOS? There are even more build environments to set up.
But we aren’t done yet. Our app’s native dependencies aren’t frozen in time. They’ll be getting new features and bug fixes that we won’t want to ignore. We’ve seen how much damage outdated dependencies can cause. Consequently, our native dependencies will continually update theirdependencies, meaning we’ll have to go through every build environment and update the supporting libraries and headers we’ve installed.
This process is starting to sound like a full-time job. Our first instinct might be to just set up containerized builds. It’s a good idea, as it’s a great way to create reusable build environments we can spin up anywhere we need — whether on a developer’s laptop or in the cloud as part of our CI/CD pipeline.
However, containerized builds may save us less work than we’d expect. We’ll still need to endure the rounds of trial and error that we’d go through when trying to set up working-build VMs. We’ll also need to maintain separate Dockerfiles for each build environment.
And if we need to support macOS, our container plan won’t work. There’s no Apple-sanctioned way of running macOS in a container. Our best option is to spin up macOS VMs running in a macOS host on Apple hardware.
After all that, we have to get the dependencies we’ve built off of each build machine so we can use them further down the CI/CD pipeline when we test and package our app.
Wow — just reading about that process is exhausting. As experienced Python developers, we can probably achieve it if necessary. But would we want to? Most of us want to spend our time writing Python, not watching over native build environments.
Reducing Complexity With the ActiveState Platform
Wouldn’t it be nice if we could avoid the pain associated with the toolchain setup? If we could download a custom-built Python distribution with freshly-built copies of our dependencies already included? If we had something we could immediately use?
The ActiveState Platform provides a turn-key secure software supply chain as a service that meets our needs in all these areas. All we need to do is tell it what version of Python we need, which operating system we’re targeting, and which libraries our application requires.
We can even add dependencies we’ve copied into private repositories. The visual dependency list reduces the risk of dependency confusion by making it obvious when we’ve accidentally added a public dependency instead of a private copy. Ensuring the correct dependencies helps boost our build’s integrity.
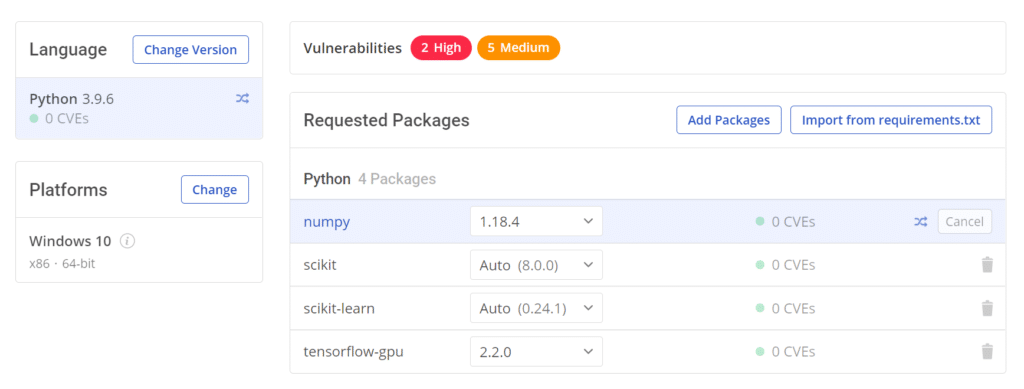
At the top of the image, we can see that the platform will even tell us if the Python version we’ve chosen, or any of our direct or transitive dependencies, contain vulnerabilities. It would take plenty of time to check for those vulnerabilities ourselves — time that most development teams don’t have.
The truth is, vulnerability scans that aren’t automated probably won’t happen at all. Not only is the ActiveState Platform much easier than DIY native dependency management — but it’s also more secure.
When we’re done selecting our Python version, target OS, and dependencies, all we need to do is commit our changes. The ActiveState Platform will take over the process from there.
It begins by building our Python interpreter from source. Then it also builds all our native dependencies from source. When it’s finished, we can easily download it through the platform website or by using the provided CLI command:
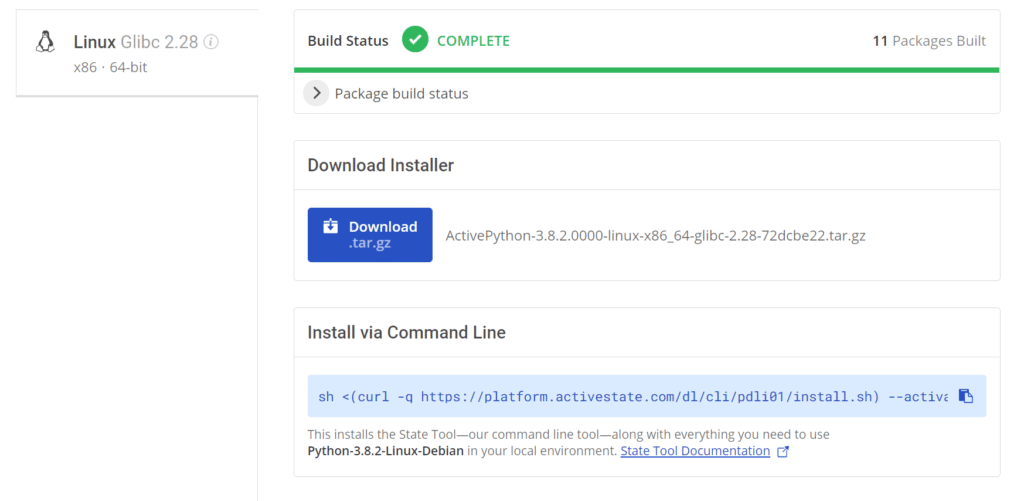
When we let the ActiveState Platform build and manage our dependencies, we spare ourselves the pain of the standard, complex, and tedious build environment setup that we examined earlier. We can use the ActiveState Platform’s builds directly in our CI/CD pipeline to run tests against our app, and then again when we package or deploy. This allows us to not only save time but also to keep our CI/CD pipeline and the rest of our software supply chain secure and consistent.
Next Steps
We’ve seen how painful it can be to build and manage native Python dependencies. Of course, if we need to, we can labor to do it ourselves and provide a less secure experience, but why would we want to? As developers, we want to spend our time developing.
Instead of spending so much time and energy building and managing your native Python dependencies, turn to ActiveState to automate and simplify the process. There’s a free tier, so you can try it before you buy with a quick and hassle-free signup. Sign up for the ActiveState Platform today to ensure consistent, reproducible development and CI/CD environments with secure package management.
If you’re interested in developing expert technical content that performs, let’s have a conversation today.