In the first article of our three-part series, we learned how tuning hyperparameters helps find the optimal settings for the best results from our machine learning model. Then, in the second article, we learned, and discovered that our tuned model makes more accurate predictions than our untuned model.
Depending on the search space, it can take a long time to execute search algorithms for hyperparameter tuning, from hours to days. When we ran the random search function in the previous article, we saw how costly it is in computing resources and time.
We want to tune our hyperparameters quicker without compromising the result’s quality. Our main bottleneck so far is using a single computer with limited resources (CPU and RAM) to try every hyperparameter combination the data set’s search algorithm produced. Each hyperparameter combination that the random search selects is independent of the previous and next selections.
We can accelerate the search by trying different hyperparameter combinations in parallel on various computers. Ray Tune can perform this distributed hyperparameter tuning by running these iterations in parallel in the cloud.
In this final article of the series, we’ll demonstrate how to use the Ray Tune library to distribute the hyperparameter tuning task among several computers. We’ll demonstrate using the distributed machine learning toolkit to tune hyperparameters on multiple local CPUs or in the cloud. We’ll continue to optimize our digit identification model, but we’ll do it quicker by distributing the task.
Porting hyperparameter tuning to Ray Tune
The Ray project has developed tune-sklearn to serve as a drop-in replacement for scikit-learn’s grid search and random search hyperparameter tuning models, GridSearchCV and RandomizedSearchCV, respectively. It also supports additional search models, like Bayesian search, tree-structured Parzen estimators, and others. It’s just a matter of setting the input parameter search_optimization to bayesian or bohb for Bayesian Optimization, or hyperopt for tree-structured Parzen estimators.
Tune-sklearn also seamlessly integrates with Ray Tune for distributed hyperparameter tuning across several machines — locally or in the cloud — without the need to change our code.
Here, we’ll adapt the code we wrote in the previous article to replace the RandomizedSearchCV() function with tune-sklearn.
First, we install tune-sklearn. In our console command line, we type one of the following:
$ pip install tune-sklearn "ray[tune]"
Or:
$ pip install -U git+https://github.com/ray-project/tune-sklearn.git && pip install 'ray[tune]'
RandomizedSearchCV with TuneSearchCV. The code’s final version is as follows, with in-line comments explaining the modifications:
import time
import numpy as np
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import xgboost as xgb
from tune_sklearn import TuneSearchCV
from sklearn import metrics
# function to perform the tuning using tune-search library
def tune_search_tuning():
# Input data files are available in the "./data/" directory.
train_df = pd.read_csv("./data/mnist_train_final.csv")
test_df = pd.read_csv("./data/mnist_test_final.csv")
# limit dataset size to 1000 samples
dataset_size = 1000
train_df = train_df.iloc[0:dataset_size, :]
test_df = test_df.iloc[0:dataset_size, :]
print("Reduced dataset size: ", train_df.shape)
y_train = train_df.label.values
x_train = train_df.drop('label', axis=1).values
y_test = test_df.label.values
x_test = test_df.drop('label', axis=1).values
params = {'max_depth': [6, 10],
'learning_rate': [0.1, 0.3, 0.4],
'subsample': [0.6, 0.7, 0.8, 0.9, 1],
'colsample_bytree': [0.6, 0.7, 0.8, 0.9, 1],
'colsample_bylevel': [0.6, 0.7, 0.8, 0.9, 1],
'n_estimators': [500, 1000],
'num_class': [10]
}
start_time = time.time()
print("starting at: ", start_time)
# define the booster classifier indicating the objective
# as multiclass "multi:softmax" and try to speed up execution
# by setting parameter tree_method = "hist"
xgbclf = xgb.XGBClassifier(objective="multi:softmax",
tree_method="hist")
# replace RamdomizedSearchCV by TuneSearchCV
# n_trials sets the number of iterations (different hyperparameter combinations)
# that will be evaluated
# verbosity can be set from 0 to 3 (debug level).
tune_search = TuneSearchCV(estimator=xgbclf,
param_distributions=params,
scoring='accuracy',
n_trials=20,
n_jobs=8,
verbose=2)
# perform hyperparameter tuning
tune_search.fit(x_train, y_train)
stop_time = time.time()
print("Stopping at :", stop_time)
print("Total elapsed time: ", stop_time - start_time)
best_combination = tune_search.best_params_
# evaluate accuracy based on the test dataset
predictions = tune_search.predict(x_test)
accuracy = metrics.accuracy_score(y_test, predictions)
print("Accuracy: ", accuracy)
return best_combination
if __name__ == '__main__':
best_params = tune_search_tuning()
print("Best parameters:", best_params)
Next, we save the code above in a .py file. For example, mnist_tune_search.py. Then we run this file from the console CLI:
$ python mnist_tune_search.py
verbose set to 2, we can expect output similar to the text below:
Reduced dataset size: (1000, 785)
starting at: 1634516904.7016492
== Status ==
Memory usage on this node: 4.9/7.7 GiB
Using FIFO scheduling algorithm.
Resources requested: 2.0/12 CPUs, 0/0 GPUs, 0.0/2.54 GiB heap, 0.0/1.27 GiB objects
Result logdir: /home/juan/ray_results/_Trainable_2021-10-18_02-28-34
Number of trials: 16/20 (15 PENDING, 1 RUNNING)
.
.
.
Trial _Trainable_53eac_00019 reported average_test_score=0.85 with parameters={'early_stopping': False, 'early_stop_type': <EarlyStopping.NO_EARLY_STOP: 7>, 'X_id': ObjectRef(ffffffffffffffffffffffffffffffffffffffff0100000001000000), 'y_id': ObjectRef(ffffffffffffffffffffffffffffffffffffffff0100000002000000), 'groups': None, 'cv': StratifiedKFold(n_splits=5, random_state=None, shuffle=False), 'fit_params': {}, 'scoring': {'score': make_scorer(accuracy_score)}, 'max_iters': 1, 'return_train_score': False, 'n_jobs': 1, 'metric_name': 'average_test_score', 'max_depth': 10, 'learning_rate': 0.4, 'subsample': 1.0, 'colsample_bytree': 0.8, 'colsample_bylevel': 0.8, 'n_estimators': 1000, 'num_class': 10, 'estimator_ids': [ObjectRef(ffffffffffffffffffffffffffffffffffffffff0100000003000000)]}. This trial completed.
== Status ==
Memory usage on this node: 4.7/7.7 GiB
Using FIFO scheduling algorithm.
Resources requested: 0/12 CPUs, 0/0 GPUs, 0.0/2.54 GiB heap, 0.0/1.27 GiB objects
Current best trial: 53eac_00016 with average_test_score=0.869 and parameters={'max_depth': 10, 'learning_rate': 0.3, 'subsample': 0.9, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.6, 'n_estimators': 500, 'num_class': 10}
Result logdir: /home/juan/ray_results/_Trainable_2021-10-18_02-28-34
Number of trials: 20/20 (20 TERMINATED)
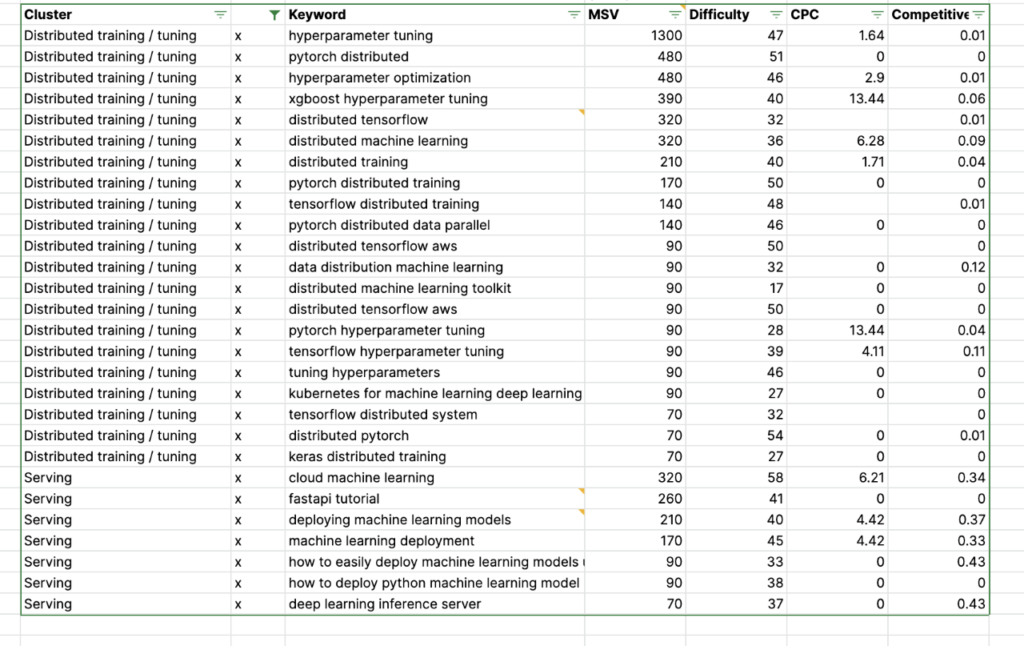
Stopping at : 1634517645.9786417
Total elapsed time: 741.276992559433
Accuracy: 0.848
Best parameters: {'max_depth': 10, 'learning_rate': 0.3, 'subsample': 0.9, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.6, 'n_estimators': 500, 'num_class': 10}
The process took over 12 minutes, and it has found the best hyperparameter combination that increases the accuracy to 84.8 percent (from 82.6 percent with the default hyperparameter values, as seen in the previous article).
Distributing hyperparameter tuning processing
Next, we’ll distribute the hyperparameter tuning load among several computers. We’ll distribute our tuning using Ray. We’ll build a Ray cluster comprising a head node and a set of worker nodes. We need to start the head node first. The workers then connect to it.
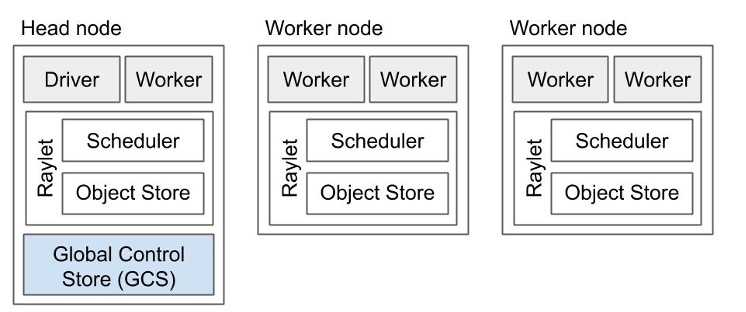
Source: Ray
First, we need to install the Ray module. In our console CLI, we enter the following command:
$ pip install ray
Note that it’s vital to ensure the environment is precisely the same on all nodes participating in the cluster for this exercise. Pay close attention to the versions of Ray and XGBoost. We’ve tested the code in this tutorial on the following versions:
$ pip show ray
Name: ray
Version: 1.7.0
$ pip show xgboost
Name: xgboost
Version: 1.2.0
Next, we make the following adaptations to our previous function:
- Copy the data files to the same directory for all nodes in the Ray cluster. Use an absolute path such as
/var/data. - Import Ray library.
- Initialize Ray to connect to the local node,
ray.init(address='auto'). - Decorate the function
tune_search_tuning()as a Ray task with @ray.remote before the function declaration. - Update the data files’ full paths to correspond with where they have been copied. For example:
/var/data/mnist_train_final.csv - Add the creation and handling of the workers to the main function.
- Move the time counter to the main function.
The new code is below, with changes commented in-line:
import time
import numpy as np
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import xgboost as xgb
from tune_sklearn import TuneSearchCV
from sklearn.model_selection import train_test_split
from sklearn import metrics
import ray
# init ray and attach it to local node ray instance
ray.init(address='auto')
# function to perform the tuning using tune-search library
# add function decorator
@ray.remote
def tune_search_tuning():
# Input data files are available in the "/var/data/" directory.
train_df = pd.read_csv("/var/data/mnist_train_final.csv")
test_df = pd.read_csv("/var/data/mnist_test_final.csv")
print (train_df.shape, test_df.shape)
dataset_size = 1000
train_df = train_df.iloc[0:dataset_size, :]
test_df = test_df.iloc[0:dataset_size, :]
y = train_df.label.values
x = train_df.drop('label', axis=1).values
y_test = test_df.label.values
x_test = test_df.drop('label', axis=1).values
# define the train set and test set
# in principle the test (valid) data is not used later,
# so we minimize the size to just 5%.
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.05)
print("Shapes - X_train: ", x_train.shape, ", X_val: ", x_val.shape, ", y_train: ", y_train.shape, ", y_val: ", y_val.shape)
# numpy arrays are not accepted in params attributes,
# so we use python comprehension notation to build lists
params = {'max_depth': [3, 6, 10, 15],
'learning_rate': [0.01, 0.1, 0.2, 0.3, 0.4],
'subsample': [0.5 + x / 100 for x in range(10, 50, 10)],
'colsample_bytree': [0.5 + x / 100 for x in range(10, 50, 10)],
'colsample_bylevel': [0.5 + x / 100 for x in range(10, 50, 10)],
'n_estimators': [100, 500, 1000],
'num_class': [10]
}
# define the booster classifier indicating the objective as
# multiclass "multi:softmax" and try to speed up execution
# by setting parameter tree_method = "hist"
xgbclf = xgb.XGBClassifier(objective="multi:softmax",
tree_method="hist")
# replace RamdomizedSearchCV by TuneSearchCV
# n_trials sets the number of iterations (different hyperparameter combinations)
# that will be evaluated
# verbosity can be set from 0 to 3 (debug level).
tune_search = TuneSearchCV(estimator=xgbclf,
param_distributions=params,
scoring='accuracy',
n_trials=25,
verbose=1)
# perform hyperparameter tuning
tune_search.fit(x_train, y_train)
print("cv results: ", tune_search.cv_results_)
best_combination = tune_search.best_params_
print("Best parameters:", best_combination)
# evaluate accuracy based on the test dataset
predictions = tune_search.predict(x_test)
accuracy = metrics.accuracy_score(y_test, predictions)
print("Accuracy: ", accuracy)
return best_combination
if __name__ == '__main__':
start_time = time.time()
# create the task
remote_clf = tune_search_tuning.remote()
# get the task result
best_params = ray.get(remote_clf)
stop_time = time.time()
print("Stopping at :", stop_time)
print("Total elapsed time: ", stop_time - start_time)
print("Best params from main function: ", best_params)
Save the code above in a file, such as mnist_ray_tune_distributed.py.
Before running the code above, you need to start a ray cluster. Extensive documentation is available in the Ray Cluster Overview docs. This documentation will show you how to start the ray cluster on any cloud provider. It includes detailed information about popular cloud providers like AWS, GCP, and Azure. However, you can also run a ray cluster locally on-premises by initiating the head node and the workers on different servers.
A simple way to set up a Ray cluster on-premises is by manually starting a head node and attaching workers to it from the command line:
$ ray start --head --port=6379
Local node IP: 192.168.0.196
2021-10-19 23:38:33,209 INFO services.py:1252 -- View the Ray dashboard at http://127.0.0.1:8265
--------------------
Ray runtime started.
--------------------
Next steps
To connect to this Ray runtime from another node, run
ray start --address='192.168.0.196:6379' --redis-password='5241590000000000'
Alternatively, use the following Python code:
import ray
ray.init(address='auto', _redis_password='5241590000000000')
To connect to this Ray runtime from outside of the cluster, for example to
connect to a remote cluster from your laptop directly, use the following
Python code:
import ray
ray.init(address='ray://<head_node_ip_address>:10001')
If connection fails, check your firewall settings and network configuration.
ray start --head command. On the rest of the nodes in the Ray cluster, enter the following in the command line, replacing the IP address with that of the actual head node in your environment:
$ ray start --address='192.168.0.196:6379' --redis-password='5241590000000000'
Once the ray cluster is running, we just need to run the Python script on one of the nodes. In the current exercise, we’ve set up a Ray cluster of two nodes. At one of the nodes, we enter the following in the command line:
$ python mnist_ray_tune_distributed.py
We expect an output like this:
INFO worker.py:827 -- Connecting to existing Ray cluster at address: 192.168.0.196:6379
.
.
.
Accuracy: 0.82
Total elapsed time: 315.5932471752167
Best params from main function: {'max_depth': 3, 'learning_rate': 0.1, 'subsample': 0.9, 'colsample_bytree': 0.6, 'colsample_bylevel': 0.9, 'n_estimators': 1000, 'num_class': 10}
The test ran in 315 seconds (approximately 5 minutes). That’s less than half the time of the previous test, where the Python script ran on a single node and took 741 seconds. Also, the new test’s accuracy is 82.0 percent for the best hyperparameter combination, similar to the results we obtained previously with the scikit-learn RandomizedSearchCV function (85.8 percent).
Distributing our hyperparameter tuning across a cluster ran much faster than on a single computer. Although our results were virtually identical to scikit-learn, we got those results faster by distributing the work.
Next steps
Manual hyperparameter tuning is slow and tedious. Automated hyperparameter tuning methods like grid search, random search, and Bayesian optimization can help us find optimal hyperparameters more quickly. Even so, tuning hyperparameters on a single computer can still take a long time. We can expedite the process by distributing hyperparameter tuning across multiple nodes, on multiple machines either locally or in the cloud.
In principle, this isn’t an easy task. It usually requires significant code refactoring. However, Ray provides the means to build distributed applications with few code changes. Using Ray Tune, we rapidly tuned our digit identification machine learning model for optimal performance.
As we saw, using Ray Tune’s TuneSearchCV to replace scikit-learn’s RandomizedSearchCV, running on a Ray cluster allowed us to easily distribute the hyperparameter tuning process across multiple nodes. This can, at most, reduce the time needed to tune by a factor of N — where N is the number of nodes in your Ray cluster — since distributed computing always has some overhead.
If you want to tune your model’s hyperparameters quickly, Ray and Ray Tune are clearly effective. Consider trying Ray Tune to improve your own models — and sign up for Anyscale if you’d like to use Ray, but don’t want to manage or scale your own cluster.
If you’re interested in developing expert technical content that performs, let’s have a conversation today.