Cloud computing has changed the way we model software and solutions. There’s a constant demand for more efficient, economic and intelligent solutions. Machine learning (ML) is powering the next breed of built-in intelligent software, while “serverless” computing is redefining how we use cloud computing platforms to attain new levels of application development simplicity, efficiency and productivity.
What is serverless computing? It’s an execution model where you upload code at the function level to a serverless cloud provider and the cloud provider is responsible for executing your code by dynamically allocating the resources. It is an event-driven model, in which your application will respond to events and triggers happening in near-real time. This model is sometimes referred to as Functions as a Service (FaaS).
In this article we’ll look at some advantages of serverless computing and then dig into a real-world example using the Microsoft Azure Functions service to build and deploy a sample ML inferencing function.
Why Serverless Computing?
There are quite a few advantages to adopting a serverless architecture for projects, whether they’re cloud applications themselves or simply use other cloud computing services.
- Cost savings: most serverless offerings are charged on a usage basis, so you pay only for the number and duration of executions of your functions — you don’t pay for idle servers.
- Low administration overhead: managing servers is a distraction for development teams. Serverless computing eliminates server management from the deployment workflow so you just focus on the logic.
- Decentralized deployment: serverless architecture follows the Microservice Principal and it allows you to deploy your model as a service by means of a RESTFul interface. It not only provides easy and fast deployment, but also isolates the service from other modules and hides the implementation details.
- Auto scaling: when using serverless architecture, you don’t need to worry about scaling. It will handle load spikes transparently and your service would continue to work smoothly even if number of requests rises significantly.
- Reusability: since service is just invoked by means of events and triggers, you can use your models for variety of tasks.
Simply saying, going serverless means you offload the hardest part of managing server infrastructure; your cloud vendor is responsible for things like scaling, networking, resources and so on. Thus, serverless computing lets you focus on is application logic and feature development logic rather than managing servers and infrastructure.
There are some potential limitations to the serverless architecture that you should take into account in project planning and budgeting. You’ll want to make sure that your cloud vendor supports languages and frameworks critical to your application and aligned with your team’s abilities. How easy is it to develop, debug, and deploy applications from your environment to the vendor’s environment. Do the cloud provider’s management and administration tools meet your needs? Can you easily integrate your serverless components with other aspects of your application, such as storage buckets, databases, and logging infrastructure?
Aside from these possible issues, I would still argue that the benefits outweigh the cost for many applications.
Serverless Architecture with Azure Functions
All the major cloud vendors are already in the game to provide serverless computing options for developers. Here are just a few of the current products available:
- Microsoft Azure Functions
- Alibaba Cloud Function Compute
- Amazon AWS Lambda
- Google Cloud Functions
- IBM Cloud Functions (using Apache OpenWhisk)
In this article we’ll take a look at Azure Functions to see how can we easily write and deploy a cloud application.
Azure Functions is Microsoft’s fully managed event-driven serverless compute experience that allows you to easily run small pieces of code in the cloud. It uses built-in triggers (HTTP, timer or any other event available from the sister Azure Event Hubs service) and bindings (Blob, Cosmos Db, Queue and so on) to connect the invoked function with input data sources or output services.
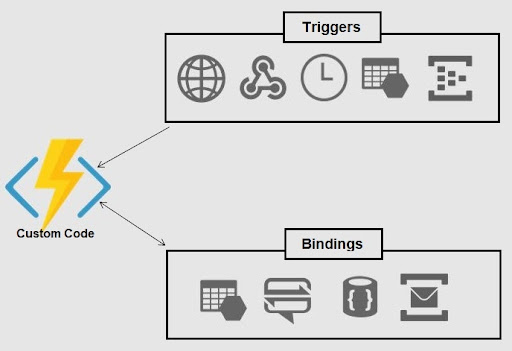
Azure Functions allow you to write functions in C#, JavaScript, F#, Java and Python (currently in preview). You can test and debug locally using your preferred IDE or the easy-to-use web based interface. When your code is ready, you can choose from a variety of deployment models including continuous deployment using App Service continuous integration and many of the popular source code repositories, ZIP upload, run directly from a package, and more.
Building a Sample ML Function
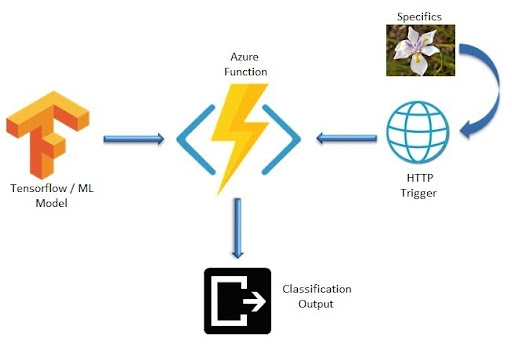
Now we’ll demonstrate using a serverless architecture using Azure Functions to create a simple ML example solution written in Python. We’ll take the classic ML example of classifying and predicting images of Iris flowers. We will be using an HTTP trigger to get an inference of Iris flower species from a trained model. The Azure Function is supposed to predict the class of the flower based on its features and return the classification as output.
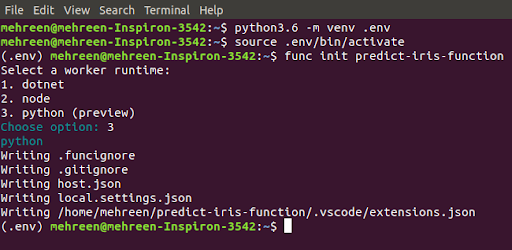
To get started you’ll need an active Azure subscription. To follow the example you’ll also need the following tools installed in your development environment:
- Python 3.6
- Azure Functions Core Tools
- Azure CLI
Once you have the prerequisites installed, create and activate a virtual environment named .env:
Choose python for the runtime.
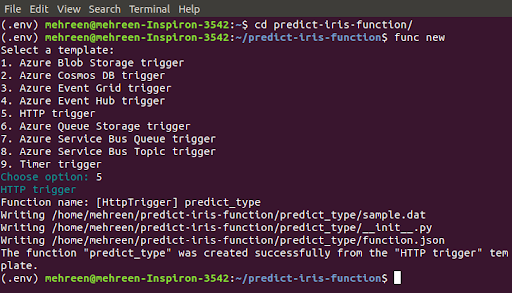
Now we need to create our desired function. Change the directory to the newly created folder and create a new function as follows:
When prompted for a template, choose the “HTTP trigger” template. Name it predict_type.
The function has been created, but it’s empty. You can run and test it, but it doesn’t do what we want right now.
Here comes the ML part. Building an entire training model is beyond the scope of this article, so I’m using a pre-trained model that can classify the species of Iris flower when specifications like petal and sepal size are given. I’m going to bind my model with the classify function.
There are certain libraries required to serve the model. Append the requirements.txt file as follows:
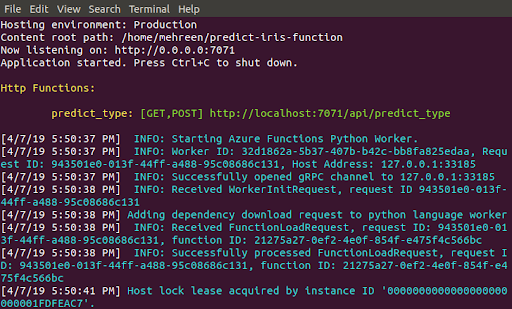
It will only take a few seconds to apply the configuration and would provide you the URL at which it is listening.
Test the deployed model by executing the following:
You can also try and test the model by specifying different values for features.
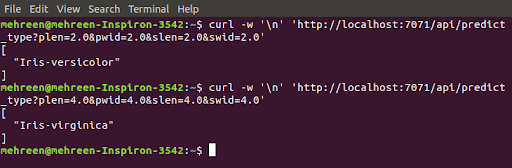
Observe the output on the other screen each time you pass the URL for inference. The HTTP trigger function is invoked and processes the request.
Publishing to Azure Functions
We’ve written the function locally and tested in a local environment. The next step is to publish our local project to Azure Functions.
You need to be connected to Azure from your local machine. Visual Studio Code lets you sign into the Azure portal and you can specify the subscription you want to use for your service deployment. Once you’re connected to the portal, search for Azure Functions: Deploy to Function App in the command pallet. Choose a unique name for the function app, resource group, storage account (you don’t need a storage account for HTTP trigger, but you may for other events) and follow the prompts. You can check the output panel as it displays all the Azure resources created.
Once deployed successfully, you can navigate to the Function App endpoint and pass your query parameters.
You can also use Docker to automatically build and configure the required binaries and Azure Functions Core Tools to publish your service on Azure. Run the following command with the name of your Linux Function App.




