This configuration defines a single container called “memory-request-limit-container” with the image limits specified in the resources section. We have specified the memory request of 256M, and we’ve limited the container to 512M.
Setting limits via namespaces
If you have several developers, or teams of developers, working within the same large Kubernetes cluster, a good practice is to set common resource requirements to ensure resources are not consumed inadvertently. With Kubernetes, you can define the different namespaces for teams and use Resource Quotas to enforce quotas on these namespaces.
For instance, you may have a Kubernetes cluster that has 64 CPU units and 256 Gigabytes of RAM spread over eight nodes. You might create three namespaces — one for each of your development teams — with the resource quota of 10 CPU units and 80 Gigabytes of memory. This would allow each development team to create any number of Pods up to that limit, with some CPU and memory left in reserve.
For more information on specifying resource quotas for namespaces, refer to the Resource Quotas section of the Kubernetes documentation.
The importance of monitoring Kubernetes
Setting requests and limits on both containers and namespaces can go a long way to ensure your Kubernetes cluster does not run out of resources. Monitoring, however, still plays an important role in maintaining the health of individual services, as well as the overall health of your cluster.
When you have large clusters with many services running within Kubernetes pods, health and error monitoring can be difficult. The New Relic platform offers an easy way to monitor your Kubernetes cluster and the services running within it. It helps you make sure that requests and limits you are setting at the container and across the cluster are appropriate.
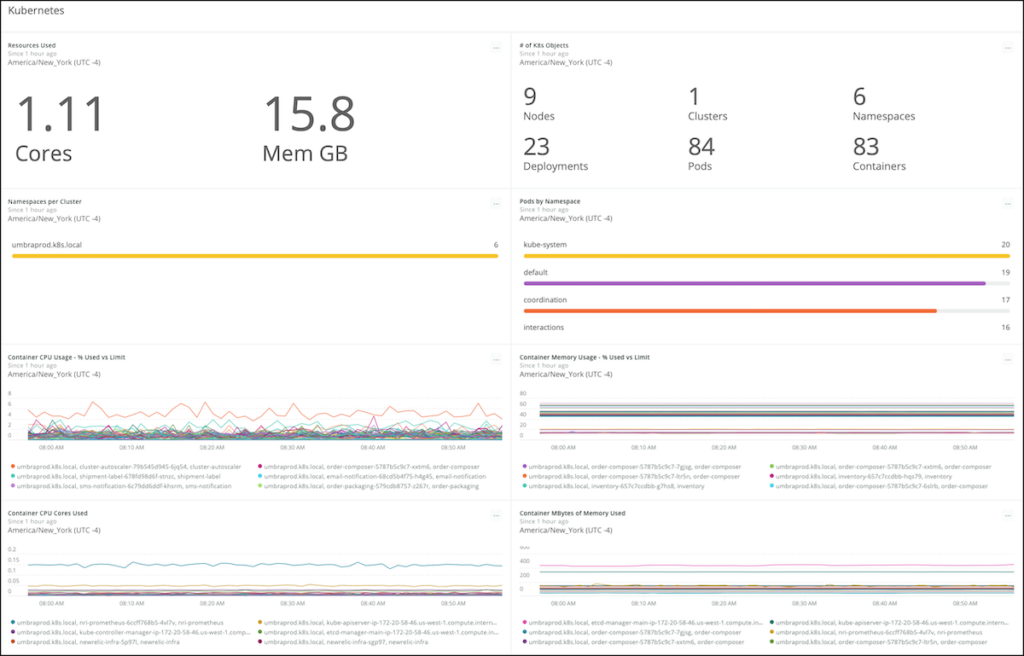
Kubernetes dashboard provides an overview of your Kubernetes platform health
Having a good understanding of how Kubernetes handles CPU and memory resources, as well as enabling configuration to manage these resources, is critical to ensure your Kubernetes clusters have enough capacity at all times. As we’ve seen, setting CPU and memory requests and limits is easy—and now you know how to do it. By adding a layer of monitoring, you will go a long way to ensuring that Pods are not fighting for resources on your cluster.
This article was originally posted on New Relic’s blog.
If you’re interested in developing expert technical content that performs, let’s have a conversation today.




