When building distributed, scalable cloud-native apps containing dozens or even hundreds of microservices, you need reliable monitoring and alerting. If you’re monitoring cloud-native apps in 2021, there’s a good chance you’ve chosen Prometheus.
Prometheus is an excellent choice for monitoring containerized microservices and the infrastructure that runs them — often Kubernetes.
However, Prometheus has an Achilles’ heel: it doesn’t scale well by default. It runs on a single machine and periodically connects to an endpoint on each of the containers, servers, and VMs it is monitoring to scrape metrics data from. Large organizations running multiple instances of each of hundreds of microservices quickly exceed the scraping capabilities of a single Prometheus server.
Prometheus stores the metrics it scrapes on a local disk in a time-series database. This is a problem because the metrics generated by growing cloud-native applications can quickly fill the disk of a Prometheus server.
Without a way to scale Prometheus, you’ll be forced to reduce the granularity of the metrics you’re collecting or start downsampling your data. Neither of these are good choices because they make the metrics you’re collecting less useful.
Scalable cloud applications need monitoring that scales with them to ensure you’re able to collect and store all of the monitoring data you need as your application grows. For a deeper dive into the factors driving the need to scale Prometheus, check out our article on Monitoring Microservices the Right Way.
Prometheus Scaling Options
Fortunately, there are several ways to build a scalable Prometheus back-end architecture that keeps up with the growth of the application it monitors. By “back end” we mean a central location to store and query data gathered by the Prometheus instances monitoring your application.
Deciding how many Prometheus instances to run — and where to run them — is a separate scaling question that depends heavily on your application architecture. A single Prometheus server can easily pull metrics from a thousand other servers.
So, you might run one Prometheus instance per datacenter if you’re monitoring physical servers, one per region if you’re monitoring cloud virtual machines (VMs), or one per Kubernetes cluster if you’re monitoring containers.
To build a scalable Prometheus back end, you have two primary choices: manual scaling using Prometheus federation and shardable solutions backed by long-term storage (LTS) that scale automatically to meet demand. You can get a general intro to the platform with our Prometheus tutorial.
Prometheus at Scale with Federation
The most straightforward way to scale Prometheus is by using federation. Simply put, federation is the ability of one Prometheus server to scrape time-series data from another Prometheus server. Prometheus offers two types of federation: hierarchical and cross-service.
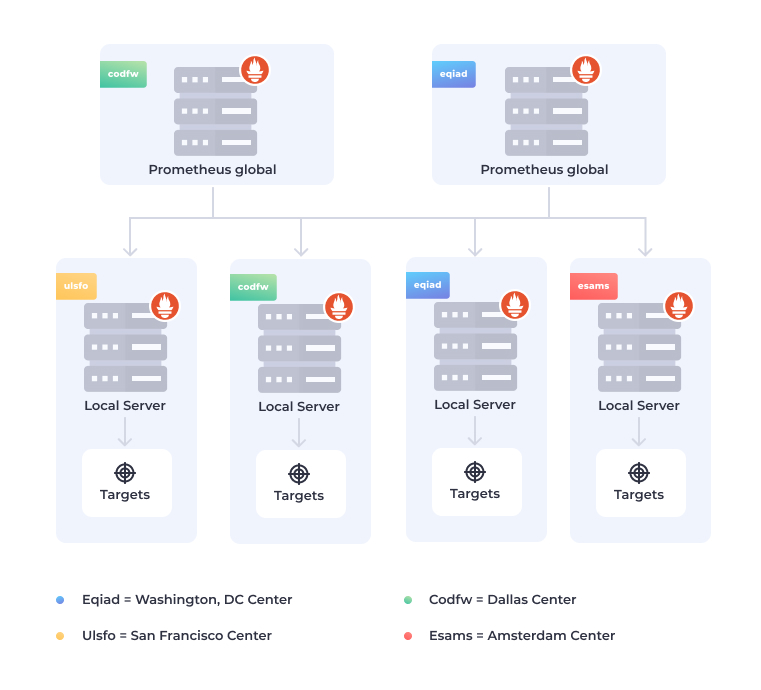
Hierarchical federation is a tree structure, where each Prometheus server gathers and stores data from several Prometheus servers beneath it in the tree. We’ll go into it a little deeper.
Hierarchical Federation
Cross-service federation is similar but simpler. Instead of pulling data from multiple Prometheus servers into a single higher-level server, cross-service federation lets a Prometheus server pull selected time-series metrics from sibling Prometheus servers. Each sibling server will contain a copy of the data it pulls from the others, so can query all of your data from any of the Prometheus servers.
Cross-Service Federation
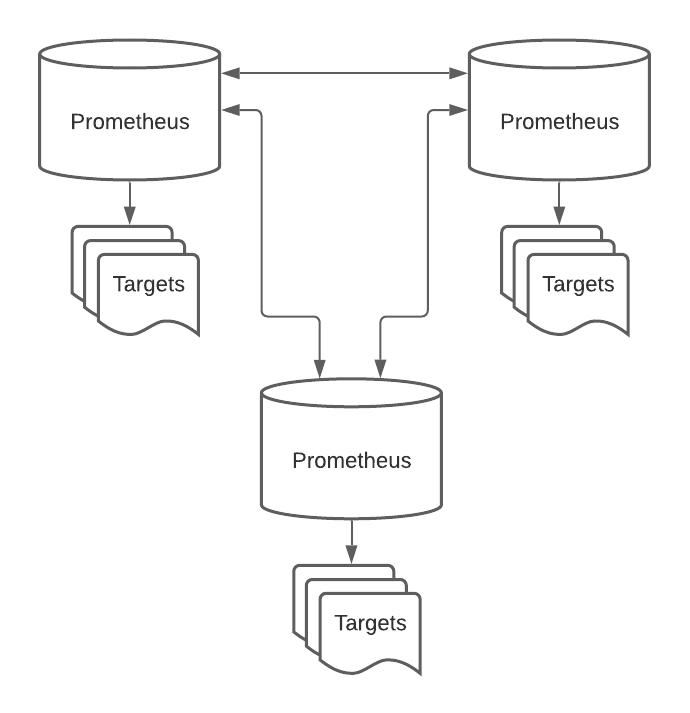
To a certain extent, both types of federations help address the distributed query issue. Instead of querying multiple Prometheus servers to get the information we need, we should query a single, federated Prometheus server.
This is especially useful for sharding Prometheus. As mentioned, a single Prometheus instance can scrape data from a thousand services. But when this isn’t enough, you can set up several Prometheus servers with each of them scraping metrics from a subset of your services. You would then set up a single Prometheus server that scrapes data from each of the shards and aggregates it in one place.
It’s also useful for rolling up metrics when you have multiple instances of the same microservice being monitored by several Prometheus servers, but you’d like to query a single Prometheus server to understand how that microservice is performing.
You can set this up quickly and easily using a recording rule that creates a reduced-cardinality time series for the parent Prometheus instance to scrape.
Drawbacks to the Cross-Service Federation Model
However, there are a couple of tradeoffs.
The first is local storage space. Since each Prometheus server stores its data on a local disk, pulling data from other Prometheus servers means we’ll have more data about what’s happening now, but we’ll end up with a shorter retention period.
You can scale up by attaching large disks to your Prometheus servers. But, as your application grows, you’ll inevitably hit a wall…
You can’t keep all the historical metrics on a single server.
Next, managing a growing fleet of Prometheus servers quickly becomes a job unto itself. You want your monitoring infrastructure to be fast and reliable. With that in mind, you’ll be on the hook for a few things, such as:
- Setting up and maintaining replicas to ensure high availability,
- Rolling out upgrades across all of your prometheus servers, and
- Scrambling to troubleshoot when something goes wrong.
Neither of these tradeoffs mean that federation is always the wrong choice for scaling Prometheus. That being said, it’s important to be aware of what you’re getting yourself into.
A Prometheus Federation Example
A common solution is to use a hierarchical federation where each level in the hierarchy only scrapes aggregate time-series data from the servers beneath it. For example, imagine you’re using Prometheus to monitor a multi-cluster Kubernetes application. Inside each cluster, a Prometheus server scrapes metrics from each pod running in the cluster.
Above these cluster-level servers, you have a single Prometheus server that scrapes aggregate metrics from each cluster-level server.
At the cluster level, you’d likely append Kubernetes metadata to each Prometheus sample — such as pod labels or node names. Those labels show you what service the pod belongs to. Node names record the physical node on which the pod and its containers are running.
Adding this metadata to each sample increases your Prometheus labels’ cardinality, which in turn increases the number of time-series Prometheus needs to store.
You’ll appreciate this tradeoff if, for example, you need to determine if an anomaly you’ve noticed in your app’s metrics only occurs on a single node.
Additional Aggregation for Prometheus
You can’t afford to ship all this data to the higher-level Prometheus server, however. You’ll have to create an additional time-series that aggregates the data using a recording rule:
If you’re trying to aggregate a metric named open_websocket_connections, you can create a recording rule that sums the number of open WebSocket connections across all pods in a service. Choose a common prefix like ‘federate:‘ when naming aggregate time-series so the federated parent server can scrape them easily.
Then, when configuring the parent Prometheus server, specify ‘{__name__=~"federate:.*"}‘ as a match parameter to ensure that the parent server scrapes aggregate data from all its children but leaves everything else behind.
Once set up, you can query the parent server about metrics from containerized services running in all your Kubernetes clusters. That is, albeit at reduced fidelity than querying each cluster-level Prometheus server individually.
Although federation works and is easy enough to understand, it’s tedious to set up and maintain. As your application grows, you’ll have to add additional layers to your federation’s hierarchy. Consequently, you’ll end up dropping more labels so you can create new aggregate time-series as you move up the hierarchy.
Is there a better approach that doesn’t involve so many tradeoffs? Ideally, we’d send all our Prometheus data to a central datastore, keep it there indefinitely, and query it at will.
Remote Storage to the Rescue
Fortunately, Prometheus can write to and read from remote storage. Prometheus has many remote storage integrations, including some names you’ll recognize, like Google Bigtable. Some datastores behind these integrations offer virtually limitless capacity, overcoming limitations imposed by Prometheus’ reliance on local storage.

Note that if you set up all your Prometheus servers to write to a remote datastore, it isn’t necessarily a scalable Prometheus architecture.
Prometheus isn’t designed to let one server remotely read data written by another server. However, you can save as much historical data as you’d like and query it at will. Also, there’s a limit to how much query traffic a single Prometheus server can handle.
This need not be a deal-breaker. If you’re comfortable with this limitation, adding a scalable cloud database as remote storage might be the last hurdle to a scalable Prometheus backend.
You can even use your database’s native query capabilities instead of running PromQL queries, but you’ll lose some excellent features.
For instance, there’s easy integration with Grafana for visualizations. Note that if you intend to use InfluxDB, OpenTSDB, or TimescaleDB for long-term storage, they have their own scale challenges.
Fortunately, a few remote storage integrations offer robust long-term storage, easy deployment and scaling, and a fast, scalable PromQL-compatible query interface.
These integrations let you stream metrics from all your Prometheus servers directly into an S3-backed time-series database.
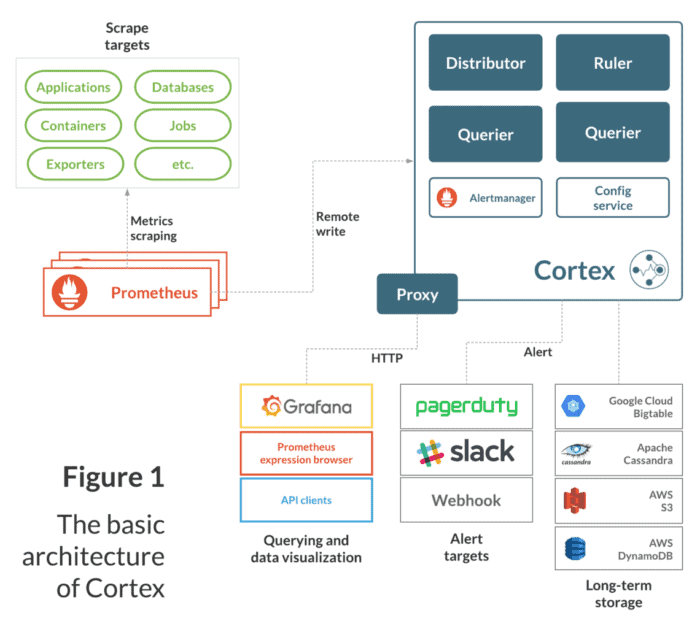
Cortex vs. Thanos
Two of the most popular integrations follow this pattern: Cortex and Thanos.
Cortex and Thanos are similar in that they offer:
- A Prometheus-compatible global query view of all time-series data collected across all your Prometheus servers
- Long-term storage backed by inexpensive object storage, such as Amazon S3
- High-availability and easy horizontal scaling
They’re also both Cloud Native Computing Foundation projects, so they’re likely to be improved and maintained over the long term.
Cortex and Thanos have a few differences.
Most notably, Cortex operates on a push model and serves as a remote write target for Prometheus servers. Cortex is a centralized solution: you push all time-series data from all your Prometheus servers to Cortex, then run all your PromQL queries and Grafana dashboards against Cortex.
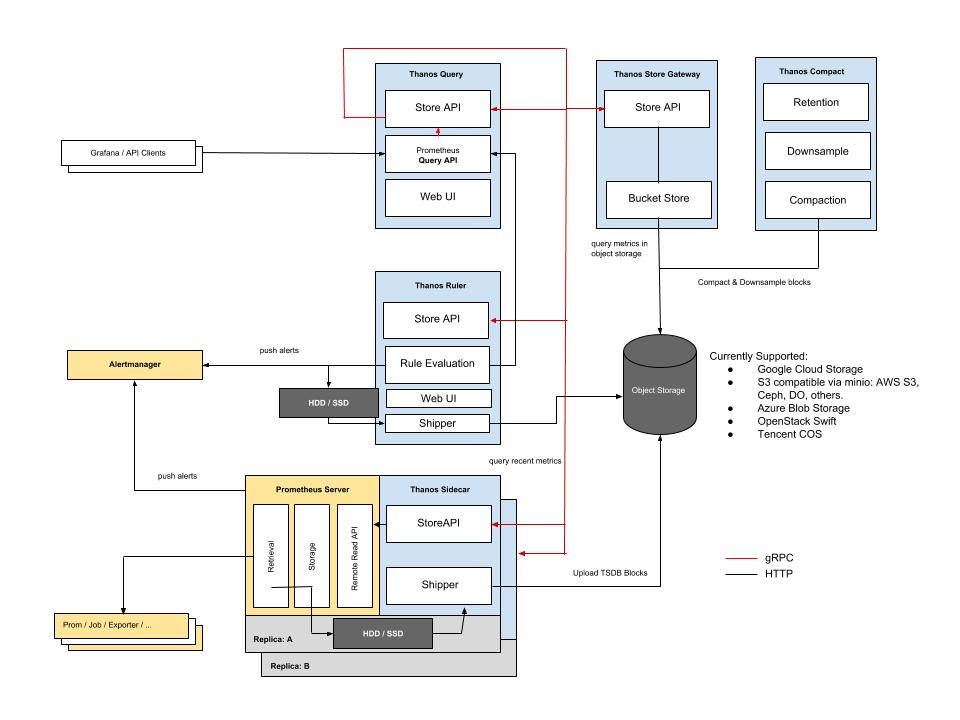
Thanos, in contrast, is more modular. It uses a sidecar process that runs alongside Prometheus servers. It then scrapes data from them and saves it to long-term object storage.
Each sidecar also presents a store API that can be called by a querier. A querier can fan queries out to multiple stores, so you’re free to set up numerous queriers. You might have one querier that can see all your data and several others only reading a subset of it.
This is useful where you’d like to let the DevOps team query everything, but limit things for other teams. Consider more limited queries so those other divisions can retrieve metrics solely relevant for the applications they own.
M3DB & VictoriaMetrics
As with most things in DevOps, there’s no one-size-fits-all solution. If you’re thinking of building a scalable Prometheus backend using Cortex, Thanos, M3, or VictoriaMetrics, consider reading through the docs. Try them hands-on to determine which one is the best fit for your team.
Note that Cortex, Thanos, M3, and VictoriaMetrics all add operational overhead. Although you can run them on a single VM, you’ll want to deploy them to their own Kubernetes cluster in practice.
All four tools offer Kubernetes operators to make deployment easy. Still, you’re adding another application your DevOps teams will have to monitor and maintain.
A Third Alternative: Outsourced Prometheus Monitoring
Federation and remote storage backed solutions are both viable ways to scale Prometheus. However, they come at high cost in terms of the time required to set up, administer, and maintain them. While these solutions might be the right choice for your organization, you instead may find they consume time and resources you’d rather devote to solving your customers’ challenges.
Fortunately, you don’t have to do all the work yourself. If you’d like the benefits of a scalable Prometheus back end without the hassle of setup and maintenance, consider a fully-managed Prometheus service like Logz.io Infrastructure Monitoring. All you have to do is add Logz.io as a remote write target for your Prometheus servers, and you’re ready to roll. You get instant access to unified queries and Grafana dashboards across all of your Prometheus time-series data — no setup or maintenance required.
Conclusion
As we’ve seen, you have several options to consider when you need to scale Prometheus. Doing it yourself has clear benefits. It might make sense if your organization is already large enough to have dedicated DevOps personnel who can devote some time to the care and feeding of your scalable Prometheus infrastructure.
If not, consider outsourcing your Prometheus infrastructure to a software-as-a-service provider like Logz.io. Instead of spending your time administering metrics, you can act on them.
This article was originally posted on Logz.io
Does your business work with Prometheus? If you’re interested in developing expert technical content that performs, let’s have a conversation today.