Introduction
Let’s say we want to group some data. Each data element has some (numeric) attributes. Using these attributes, we want to split the data into different clusters. For us humans this often can be done just by looking at the data. For a computer, this is harder to determine.
Of course, we (humans) can only “see” this if the data does not have too many dimensions, if the data set is not too big, and if the number of clusters is limited. If the data gets more complex, we’ll require a computer.

The code for this article can be found at https://github.com/GVerelst/ArtificialIntelligence.
Prerequisites for this article
![]()
The sample code in this post is in F#, so some knowledge of this language is needed. There are good places on the web to learn this and I have put some of the better ones in the references section at the end. A good understanding of the |> operator will help.
What are some examples of clustering?
E-commerce
We can have an e-commerce site with sales history per person. Maybe it would be nice to know whether a customer is a hobbyist so we can recommend some power tools. Or maybe they ordered a lot of DVDs before, so we can recommend them specific DVDs (or a DVD player).
For the DVDs, we might be able to find out the genres that this customer is interested in and propose some more interesting items to this customer.
Image compression
Bitmaps are composed of RGB values. These values are sometimes just a little bit different, not visible to the human eye. But if we can cluster the millions of colors into a set of, say, 100 different colors, we may be able to compress the bitmap size. Or we may be able to discover shapes inside the image.
How does the algorithm work?
Let’s start with clustering points on a line.
The inputs for the algorithm are:
- The point values
- The number of clusters that we want. This is the k in k-means. This algorithm will only try to make k clusters, where k is determined by the caller. It would be possible to run the algorithm with different k’s and then find the best way, but that is out of the scope of this article.
Further inputs can be:
- How will we calculate the distance between points?
- If you want the results to be repeatable: a seed value for the randomizer.
Using a functional language this can easily be done by passing the right functions into the algorithm.
Below we see a line with points at { 1, 2, 3, 7, 8, 10, 11, 15, 16, 18 } :

We want to divide this in 3 clusters (k = 3). Looking at the line we see that we’ll probably end up with clusters { 1, 2, 3}, { 7, 8, 10, 11 } and { 15, 16, 18 }.
Steps for k-means clustering
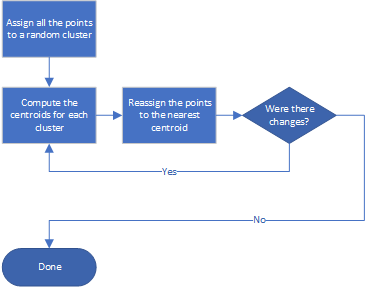
- Assign all the points to a random cluster, making sure that no cluster is empty.
- Loop:
- Compute the centroids for each cluster
- Reassign the points to the nearest centroid
- Until there are no more changes
This is a typical flow for an optimization problem. First assign random values, then refine until a good solution is found.
What is this “centroid”?
The centroid is typically the “average” for each cluster. When we talk about single values, this means calculating the average of the values in each cluster. When we have more attributes in each item, we want to calculate the average value for each attribute. For example, in a cluster C, we have points {x, y}. The centroid will be the point with
- x = average of all the x values in the cluster,
- y = average of all the y values in the cluster.
What does “nearest” mean?
The nearest point to another point is the point at the smallest distance from this point.
For each point, we are going to calculate the distance to each centroid, and then assign the point to the cluster with the nearest centroid.
A valid distance d(x, y) means:
- Positive. \(d(x, y) ge 0\). (d(x,y) = 0) only when (x = y)
- Symmetric. (d(x,y) = d(y,x))
- Triangle inequality. (d(x,y) + d(y,z) ge d(x,z))
There are a couple of different ways to calculate a distance between two points. We will create a separate function to calculate the distance.
In our case, we could suffice with (left | x-y right |). Alternatively, we could also use (sqrt{left ( x-y right )^{2}}), which will always be possible as well. This brings us closer to the Euclidian distance.
When we want to calculate the distance between two points we get:
\(d left( left( x_{1},y_{1} right ),left ( x_{2},y_{2} right ) right )=sqrt{left ( x_{1}-x_{2} right )^{2}+left ( y_{1}-y_{2} right )^{2}}\)This is extensible to more attributes.
For the clustering algorithm, we are not interested in the exact distance, but we only want to know which centroid is nearer to a point. So there is no need to calculate the (expensive) square root.
On Wikipedia, this is explained in great detail: https://en.wikipedia.org/wiki/Distance
For our algorithm, we don’t need to calculate the square root because we are not interested in the exact distance between two points. We only want to know which centroid is the nearest be a point.
Let’s work out this example, with what we have learned so far
Iteration 0 (initialization)
This is the same data set as before, grouped randomly in three clusters: orange, yellow and green. For each cluster we now calculate the centroid:

I have added the centroids in the chart below. They are on the highest line.

Iteration 1
The next thing to do is to find out for each point which centroid is closest. For each point, we now calculate the distance to all the centroids, and we assign the point to the nearest centroid’s cluster. This gives us the following chart:

We can see that the situation is better and that the centroids are moving as well. The orange cluster currently only holds one item, but that will change.
Iteration 2

Iteration 3

This is the final solution. The algorithm has calculated new values, but they were equal to the previous ones. So, this is the best solution.
What you need to know about F# to follow the code
The pipeline operator |>
When in the code we see
let centroids = values |> calcCentroids
this is the same as
let centroids = calcCentroids values
We can look at this like: the values collection is sent into the calcCentroids function.
With just one function in the pipeline this is not very useful (and mainly a matter of personal preference and code consistency) but looking at how we call the algorithm this starts to make sense:
getValues |> assignRandomClusters k |> algo calcIntDistance |> showClustered
We send the output from getValues to the assignRandomClusters function as a second (hidden) argument. The output from this function is then sent into the algo function (hidden argument), and finally, the output from algo is sent into showClustered (hidden argument).
Structuring the code like this immediately makes all the steps that have been taken clear. It is more readable than
showClustered (algo calcIntDistance (assignRandomClusters k getValues))
Lists
Typically, functional languages work with immutable lists. There are a lot of functions that can be used to handle elements in a list, often working on the whole list at once. This explains why we don’t need loops.
Some of the functions are:
List.iter
Example:
values |> List.iter (printfn "%A")
For each list item, the procedure (printfn "%A") will be called.
List.map
xs |> List.map (fun y -> {x = y; cluster = random.Next(k)} )
for each list item, the function will be called. A new list with the results of the function will be returned.
List.groupBy
rows |> List.groupBy(fun r -> r.cluster)
This will return a list of lists, for each different value of r.cluster.
I have used some more functions, but they are self-explanatory.
Creating the project
I used Visual Studio 2017 to create this project:
- File > New > Project…
- Choose Other Languages > Visual F# > .NET Code -> Console App (.NET Core)
- Give the project a good name and location, then click OK. A new F# project will be created.
Show me the code!
The code for this example is only 55 lines of F#. If you’re going to check out the code from Github, you’ll notice that there are actually 68 lines. This is because I also provided a condensed version of the algo function. You can find the implementation of the algorithm here: https://github.com/GVerelst/ArtificialIntelligence/blob/master/ArtificalIntelligence/KmeansOneValue.fs.
Data structures
[<StructuredFormatDisplay("[x:{x}, c:{cluster}]")>]
type Row =
{
x: float;
cluster: int;
}
This is the data row. In this case, it only contains a float x as a data item, and as explained before, the cluster that it belongs to. The StructuredFormatDisplay attribute makes the printfn function output the Row in a nice way.
To make the code simple, I created a Row with 1 data point (x). To make things more generic we can change this into a float list. This would allow having multiple values per row.
A second design choice I made was to keep the cluster with the data. Another possibility would be to create a new list for each cluster.
Presentation functions
showData
Let’s start with the showData function, which is trivial:
let showData values =
values |> List.iter (fun r -> printfn "%A" r)
It runs over the collection and prints each element on a new line.
If you want to write this more concise, then you can make use of currying:
let showData values =
values |> List.iter (printfn "%A")
This will output the collection in the same way. Notice that the data type for showData is not specified. This makes the function polymorphic. And this is where StructuredFormatDisplay comes in.
showClustered
The showClustered function outputs the same list of values but grouped per cluster.
let showClustered values =
values |> List.groupBy(fun r -> r.cluster)
|> List.iter(fun (c, r) ->
printfn "Cluster %d" c
r |> showData)
Initialize the randomizer
let random = new Random(5);
I am using a Random with a seed of 5. This will always generate the same series of random numbers, so the output of the program will be the same. In real life, this is not necessary, and you can instantiate a Random with no arguments.
let getValues = [ 1.0; 2.0; 3.0; 7.0; 8.0; 10.0; 11.0; 15.0; 16.0; 18.0; ]
This function returns the data. For the demo program, the data is a hard-coded list. The data can also be read from a file, which is more realistic.
Helper functions
Now that the plumbing is out of the way, we can move towards the actual implementation.
calcIntDistance
let calcIntDistance t u = Math.Abs(t.x - u.x)
This function is used to calculate the distance between the centroids and the data points. I chose a very simple implementation, as you can see. This function will be passed as a parameter into the algorithm so that it can easily be replaced. This will be necessary when rows have more properties to take into account.
assignRandomClusters
This function divides the original data set in k random clusters. Using F# helps to make this function a one-liner. All it does is mapping each element (x) to a new Row, together with a random number between 0 and k-1. If you want to make this more foolproof, you can verify that none of the clusters is empty. I have implemented this test in the KmeansGeneric module.
let assignRandomClusters k xs =
xs |> List.map (fun y ->= y; cluster = random.Next(k)} )
k is passed as a parameter. This is the only place where we need to know the number of clusters.
calcCentroids
let calcCentroids rows =
rows |> List.groupBy(fun r -> r.cluster)
|> List.map(fun (c, r) ->
{
x = r |> List.averageBy (fun x -> x.x);
cluster = c
})
You guessed it, this function will calculate the centroids for each cluster. The steps are
rows |> List.groupBywill split the collection of rows per cluster. The result is a list of lists.List.mapwill calculate the centroid for each cluster. This means taking the average from the cluster rows and adding the cluster number to it.
F# shines again in its conciseness!
The actual algorithm
Now that all the helpers are in place, not much is left for the actual calculation of the cluster.
let rec algo calcDistance values =
printfn "nLoop"
values |> showClustered
printfn "Centroids"
let centroids = values |> calcCentroids
centroids |> showData
let values' = values |> List.map (fun v ->
let shortest = centroids |> List.minBy(fun c -> calcDistance c v)
{ v with cluster = shortest.cluster }
)
if values = values' then values'
else algo calcDistance values'
Because this is a demo program, there is some output which you would leave out in a production program. The steps in the algo function are
- Calculate the centroids using the
calcCentroidsfunction - For each row in values find the nearest centroid and assign it to this row. More correctly we instantiate a new row with the new cluster value. The actual calculation is a pipeline where we
- Calculate the centroids for all the values (which is actually the data with the currently assigned clusters)
- For each centroid, we calculate the distance to the current point v
- We then find the minimum of these values. This is the cluster that v will belong to now.
- Test if there is a change between the newly calculated values and the original values. If there is no change we are ready, otherwise we send values’ back into the algorithm.
For the more concise version, profiting more from the |> operator:
let rec algo calcDistance values =
let values' = values |> List.map (fun v ->
let shortest = values |> calcCentroids
|> List.minBy(fun c -> calcDistance c v)
{ v with cluster = shortest.cluster }
)
if values = values' then values'
else algo calcDistance values'
Using the algorithm
Calling the algo function:
getValues |> assignRandomClusters k |> algo calcIntDistance |> showClustered
In this pipeline we
- Get the values to be clustered
- Assign them to random clusters, with k being the number of clusters
- Call the recursive clustering algorithm, with
calcIntDistancebeing the function that will calculate the distance between two points. This allows inserting different functions if desired. - And finale output the clustered data.
The actual k-means algorithm is this: assignRandomClusters k |> algo calcIntDistance
Caveats
The algorithm is not perfect for a couple of reasons.
- One of the clusters can end up empty. This will mean that we will end up with n – 1 clusters and that is probably not the desired result. When this happens, we must restart with new random values.
- In rare cases, the algorithm may not terminate. To avoid this, we must pass a parameter to limit the number of iterations through the algorithm. For a collection of n elements, this parameter is typically set to n².
- The algorithm is not deterministic. Depending on the initial cluster values, other cluster combinations can be found. Running the same program multiple times can yield different results. K-means is an optimization solution, and there can be more than one (local) optimal solution.
- Because of this, we are not sure if we have found “the best” solution. A solution for this is to measure how well the results are clustered and run the algorithm multiple times. We then take the best of all the solutions. This is out of scope for this article.
- The data is not normalized. With only one value in the rows, this is not a problem. When a row contains more values (say x and y) where x has values between 0 and 1 and y has values between 40000 and 50000. Calculating the distance between two rows will almost ignore the x values. This can be resolved by normalizing both x and y so they fall in the same data ranges.
Extending this example
We made a simple example where rows only have one attribute, x. To extend this into clustering in a plane, you can add an attribute y. Besides the Row type and the getValues function, there are only two places where the code must be adapted:
- You’ll need a new
calcDistancefunction, using x and y to calculate the distance. - In the
calcCentroidsfunction, you’ll also need to assign the y value.
Both problems can be solved by making the type Row more generic, but for the sake of simplicity, I left it as it is.
Conclusion
Clustering is an optimization problem. Often these problems are solved by first generating a random solution, and then refine this into an acceptable solution. It is never guaranteed that the solution will be perfect.
F# is a great language to use to implement such algorithms because of its conciseness, type inference, and immutability.
I implemented a more generic version of the algorithm that works with a list of floats in the data row, instead of just one x. This implies some changes in the code.
calcListDistanceis implemented as the sum of the squarescalcCentroidsbecame a bit more complicated, but essentially it does the same- Some cosmetics.
I have provided the code for this, but I will not discuss it further because only some details change. See https://github.com/GVerelst/ArtificialIntelligence/blob/master/ArtificalIntelligence/KmeansGeneric.fs.
References
General
- https://en.wikipedia.org/wiki/Distance
- https://quoteinvestigator.com/2010/12/07/foul-computer/ About the author of the quote at the start of this article.
k-means algorithm
- https://www.syncfusion.com/ebooks/machine – Free e-book about machine learning.
- K-means & Image Segmentation – Computerphile
- StatQuest: K-means clustering
- 12. Clustering
F#
- https://fsharpforfunandprofit.com/ This is the reference for F#!
- https://fsharpforfunandprofit.com/posts/function-composition/ In the code I use the F# pipeline ( |> ) a lot. Here you can find out more about it.
- https://fsharpforfunandprofit.com/posts/designing-with-types-single-case-dus/ An explanation of the union type that is used to describe the Row type.